Unlike humans, who can effortlessly estimate the entirety of objects even when partially
occluded, modern computer vision algorithms still find this aspect extremely challenging.
Leveraging this amodal perception for autonomous driving remains largely untapped due to the
lack of suitable datasets. The curation of these datasets is primarily hindered by significant
annotation costs and mitigating annotator subjectivity in accurately labeling occluded regions.
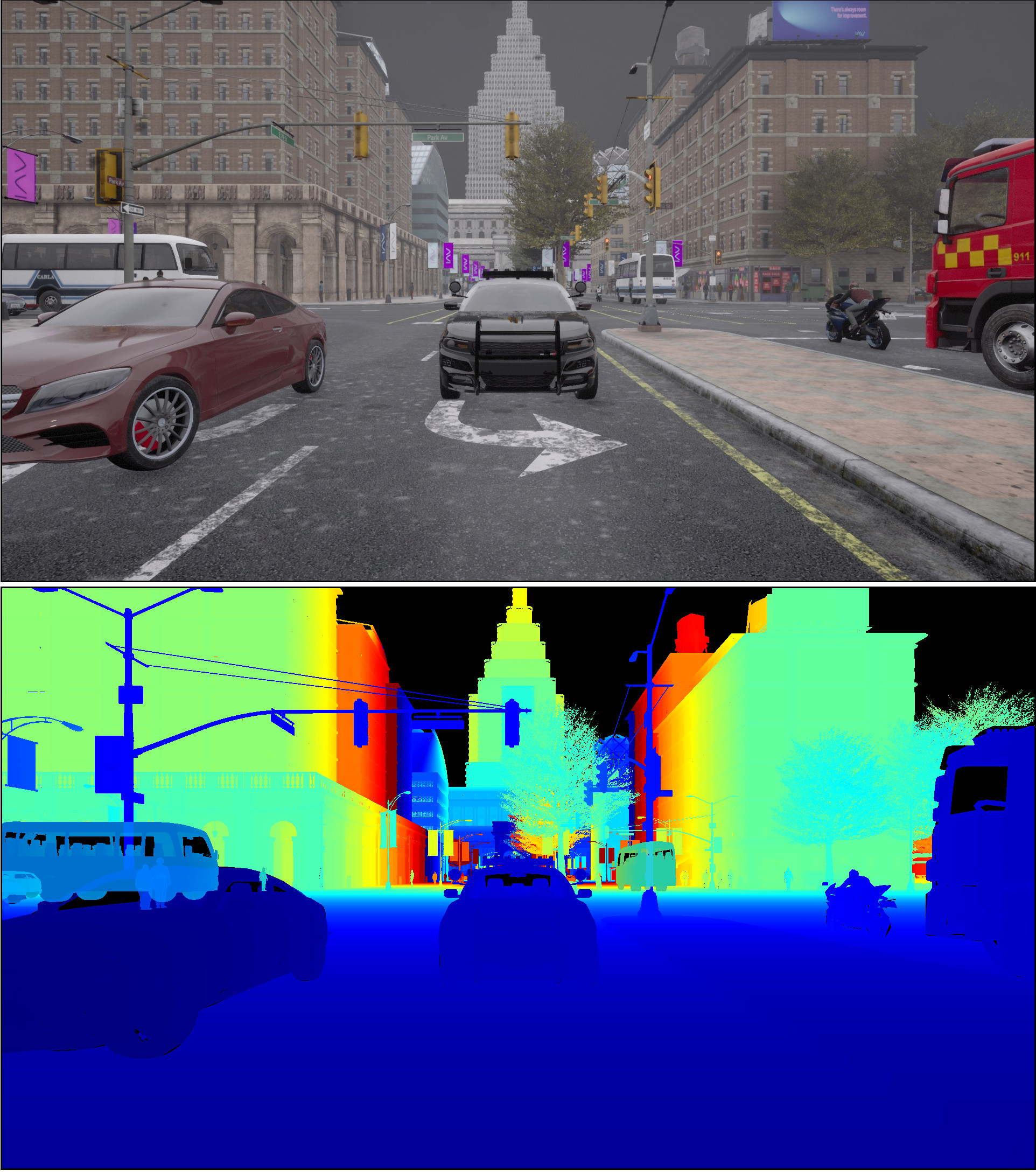
To address these limitations, we introduce AmodalSynthDrive, a synthetic multi-task multi-modal
amodal perception dataset. The dataset provides multi-view camera images, 3D bounding boxes,
LiDAR data, and odometry for 150 driving sequences with over 1M object annotations in diverse
traffic, weather, and lighting conditions. AmodalSynthDrive supports multiple amodal scene
understanding tasks including the introduced amodal depth estimation for enhanced spatial
understanding. We evaluate several baselines for each of these tasks to illustrate the
challenges and set up public benchmarking servers. The dataset is available here.